Wonjun JoI am a Ph.D. candidate in the Department of Electrical Engineering at POSTECH. I conduct my research at the Advanced Machine Intelligence (AMI) Lab at KAIST, advised by Prof. Tae-Hyun Oh. I am interested in Self-supervised Learning and Multi-modal Learning for preserving and improving the generalization capability of World Models, toward robust Embodied AI and real-world robotics. More specifically, my recent research focuses on Vision-Language-Action (VLA) and World Action Models (WAM) for robotics, with additional interest in sound, tactile, and force signals for holistic world understanding.
|

|
Research
|
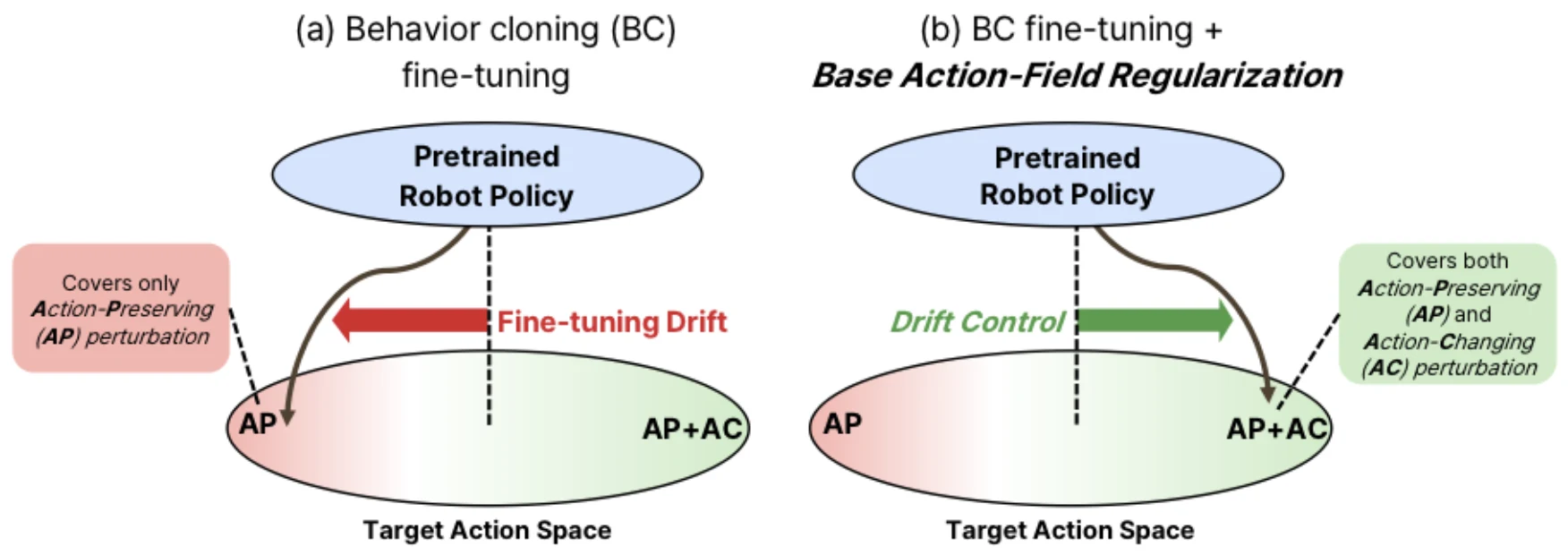
When Fine-Tuning Drifts: Mitigating Policy Drift with Base Action-Field Regularization
Wonjun Jo, Nam Hyeon-Woo, Yohan Park, Hyunwoo Ha, Tae-Hyun Oh Under review, 2026 Project Page | Paper Mitigating policy drift for robust few-shot fine-tuning of pretrained robot policies. |
|
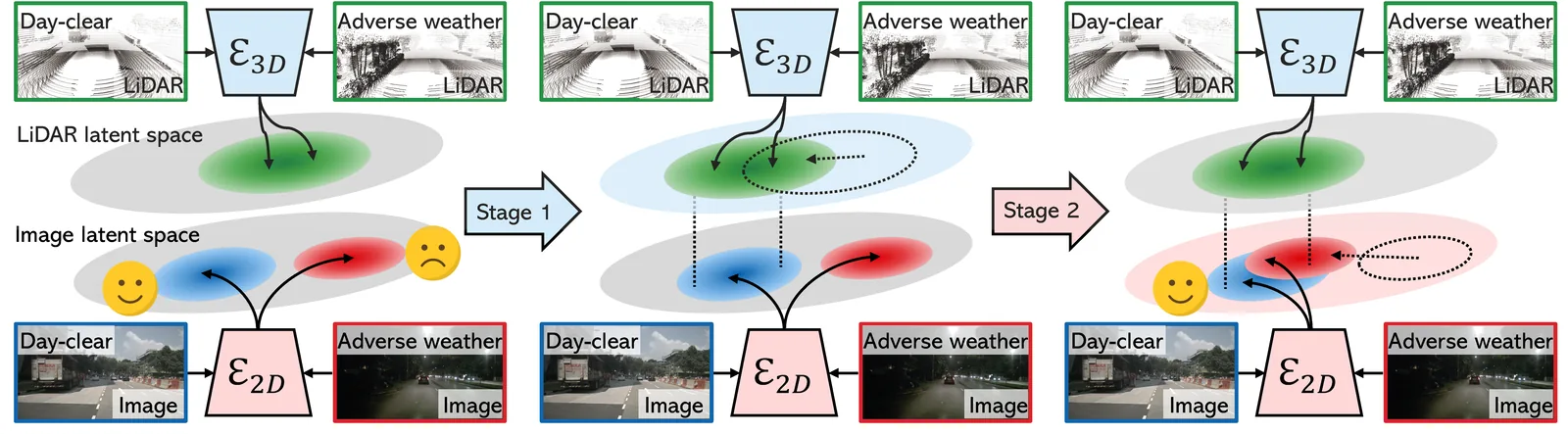
LiDAR-Anchored Collaborative Distillation for Robust 2D Representations
Wonjun Jo, Hyunwoo Ha, Kim Ji-Yeon, Hawook Jeong, Tae-Hyun Oh IEEE Robotics and Automation Letters (RA-L), 2026 Project Page | Paper Improving the robustness and generalization of self-supervised visual representations with LiDAR guidance. |
|
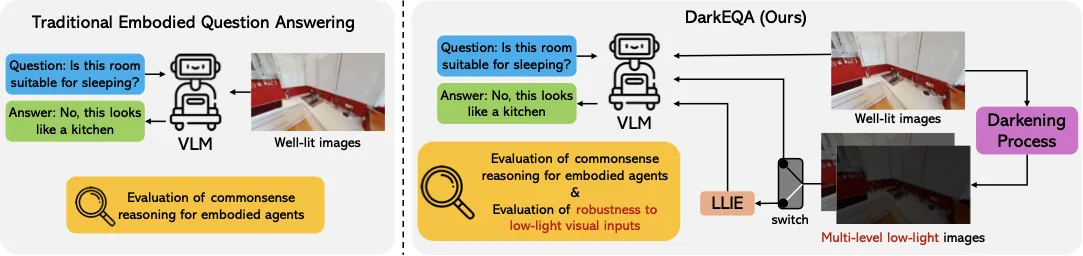
DarkQA: Benchmarking Vision-Language Models on Visual-Primitive Question Answering in Low-Light Indoor Scenes
Yohan Park, Hyunwoo Ha, Wonjun Jo, Tae-Hyun Oh IEEE Robotics and Automation Letters (RA-L), 2026 Project Page | Paper Benchmarking the robustness of embodied vision-language models under low-light conditions. |
|
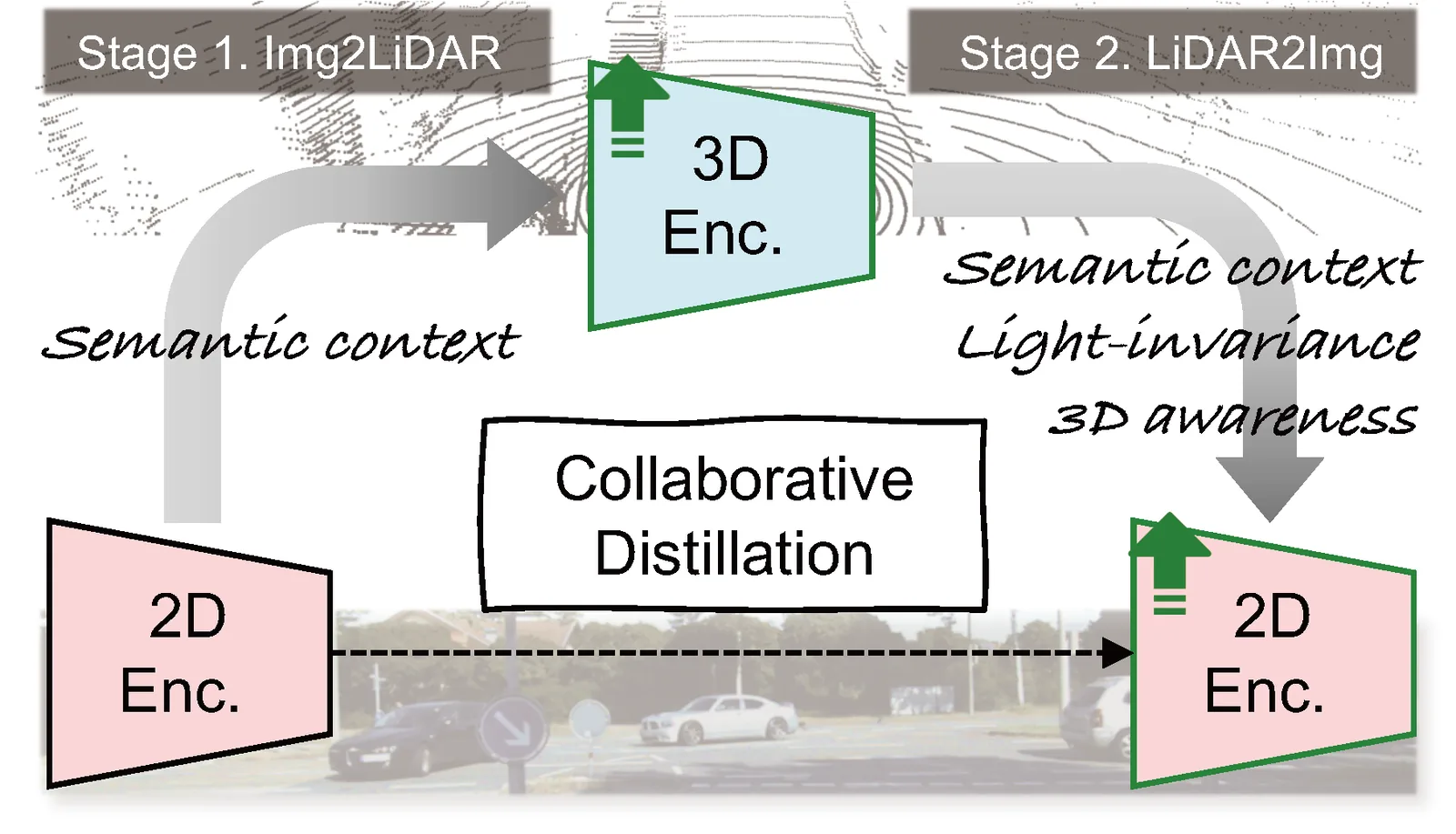
Self-Supervised Collaborative Distillation: Enhancing Lighting Robustness and 3D Awareness
Wonjun Jo, Hyunwoo Ha, Kim Ji-Yeon, Hawook Jeong, Tae-Hyun Oh Workshop on Wild3D, IEEE/CVF International Conference on Computer Vision (ICCV), 2025 Paper Improving pretrained visual representations for lighting robustness and 3D-aware generalization. |
|
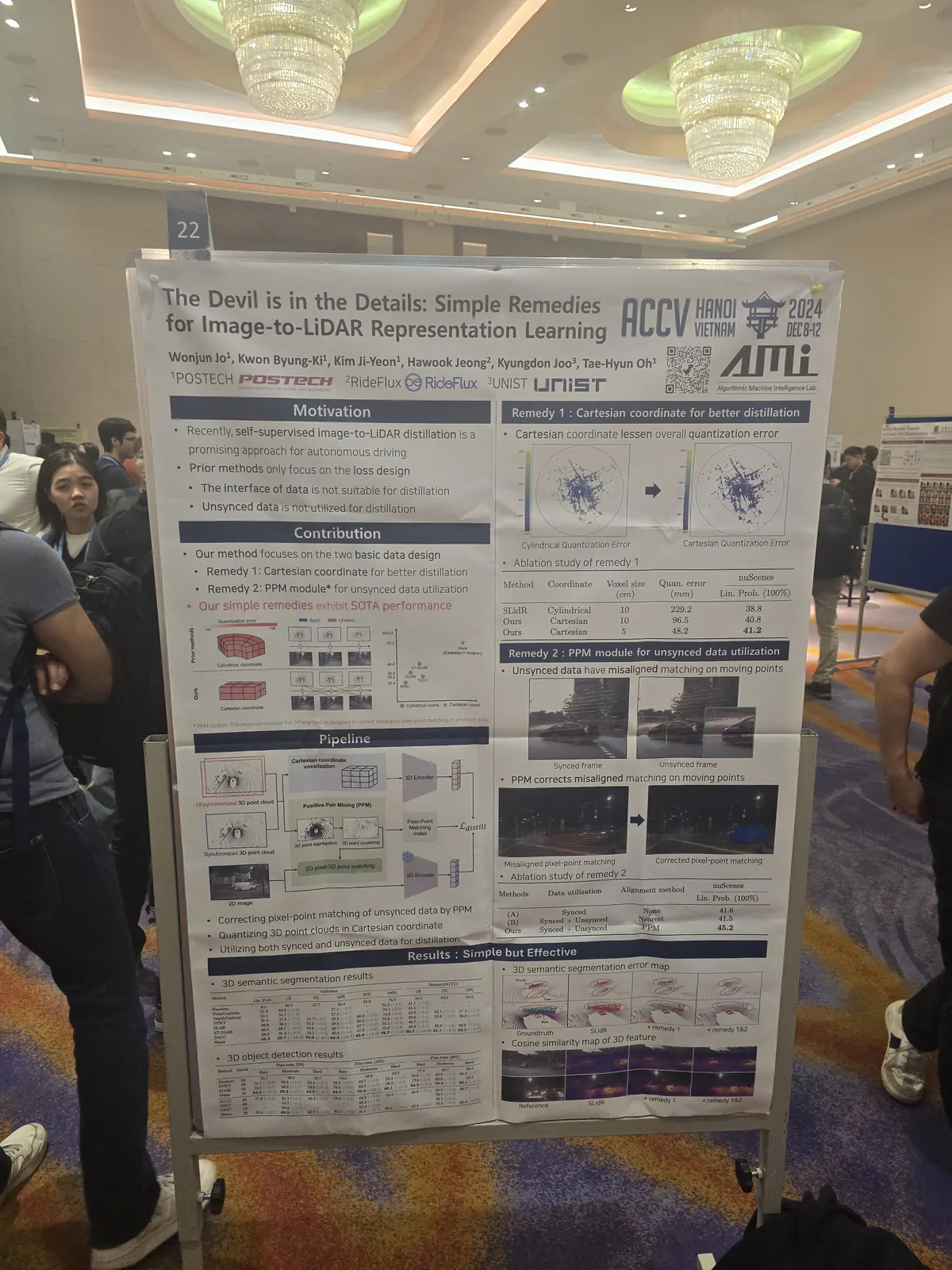
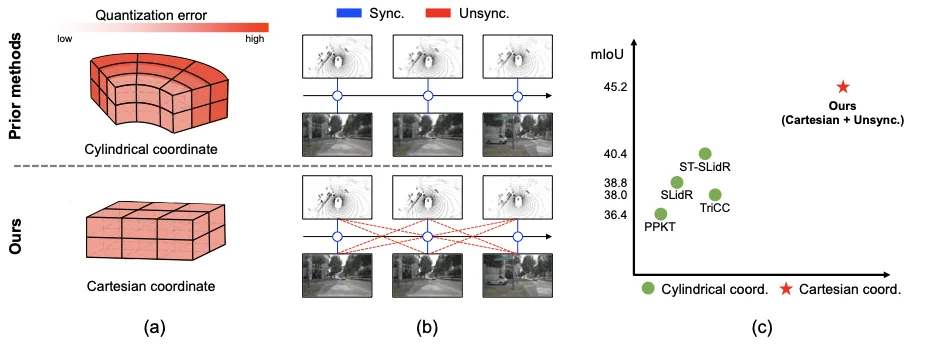
The Devil is in the Details: Simple Remedies for Image-to-LiDAR Representation Learning
Wonjun Jo, Kwon Byung-Ki, Kim Ji-Yeon, Hawook Jeong, Kyungdon Joo, Tae-Hyun Oh Asian Conference on Computer Vision (ACCV), 2024 Project Page | Paper Improving self-supervised image-to-LiDAR representation learning for robust 3D perception. |
Experience
|
|
KIST Physical AI Research Scientist Internship
Korea Institute of Science and Technology Jul. 2026 - Present Advisor: In So Kweon World models for physical robot AI agents. |
|
|
POSTECH Student Internship
Pohang University of Science and Technology Jun. 2021 - Aug. 2021 Advisor: Tae-Hyun Oh Knowledge distillation for human mesh reconstruction. |
Notes
|
Research Core
Self-Supervised Learning
Multi-Modal Learning
World Models
Embodied AI
Energy-Based Models (Yann LeCun)
Free Energy Principle (Karl Friston)
|
Music
|
No Time for Caution Hans Zimmer YouTube |
|
|
Can You Hear The Music Ludwig Goransson YouTube |
|
|
Time Hans Zimmer YouTube |
|
|
We Have to Go Steve Jablonsky YouTube |
|
|
Cloud Atlas End Title Tom Tykwer, MDR Rundfunkchor, MDR Sinfonieorchester YouTube |
|
|
Tears in the Rain Hans Zimmer, Benjamin Wallfisch YouTube |
|
|
Seven Worlds One Planet Suite Hans Zimmer YouTube |
|
|
Contact - End Credits Alan Silvestri YouTube |
|
|
Transformation (End Titles) Hans Zimmer YouTube |
|
|
Leaving Caladan Hans Zimmer YouTube |
|
|
You Don't Have To Kris Bowers YouTube |
|
|
F1 Hans Zimmer YouTube |
|
|
Believe in the Hail Mary Daniel Pemberton YouTube |
Photo
|
ICCV 2025 Date: October 2025 Location: Honolulu, Hawai'i, USA 







|